
.webp)
Why the logistics industry’s obsession with frontier models is an expensive distraction, and what to build instead.
Most teams deploying vision-language models in logistics are solving the wrong problem.
They start with a reasonable-sounding question: Which foundation model should we use for shipping label extraction? They benchmark GPT-4o against Gemini against Qwen on a curated sample of FedEx and UPS labels, pick the winner, wrap it in an API call, and demo it to operations. Accuracy looks respectable. Stakeholders nod. Someone says “AI-powered.”
Then reality arrives. A thermal-faded DHL Waybill. A crumpled customs declaration half-covered by packing tape. A USPS Priority Mail label photographed at 30 degrees under fluorescent lighting on a brown cardboard background. Suddenly, your 80% accuracy on clean samples collapses to 60% on the warehouse floor, and every missed field means a package either goes to the wrong continent or sits in an exception queue, burning labor hours.
The question these teams should be asking is not which model, but whether my domain belongs in a general-purpose model at all.
I’ve spent the past year building vision-language models for logistics document understanding at PackageX, shipping labels across 300+ carriers, bills of lading, customs forms, and proof-of-delivery slips. The work spans the entire chain: from on-device VLM inference on iPhones at the point of scan, to on-premise vision systems running fixed cameras on warehouse docks, to backend extraction pipelines processing millions of documents.
Here’s what that work taught me:
The Logistics Document Problem Is Deceptively Hard
Logistics documents occupy an awkward gap in the VLM landscape. They’re too visual for pure NLP; you can’t extract a tracking number from a barcode using text models. They’re too structured for general vision models; a shipping label isn’t a photograph to be captioned, it’s a data-dense artifact where spatial relationships between fields carry semantic meaning.
Consider what a VLM actually needs to understand when processing a single shipping label:

This isn’t image captioning. The model needs to simultaneously identify the carrier (from a logo, a layout pattern, or a barcode prefix), use that identification to activate carrier-specific parsing rules (FedEx Ground labels have different field layouts than FedEx Express), extract structured data from multiple zones (addresses, tracking numbers, service codes, weights, dimensions), validate internal consistency (does the routing code match the destination ZIP?), and produce machine-readable output that can be written directly to a WMS or TMS.
A general-purpose VLM can do some of this. It can read text. It can identify barcodes. But it has no concept of how carrier identification changes the parsing strategy, no awareness that a specific barcode placement pattern means “this is a return label, not an outbound shipment,” and no training on the visual conventions that warehouse workers learn in their first week on the job.
The Prompt Engineering Ceiling in Logistics
Every logistics AI team I’ve observed follows the same trajectory. I’ve watched it happen internally, I’ve seen it in customer conversations, and I’ve replicated it myself at the start of this work. The pattern is so consistent it’s almost a law.

Stage 1: The impressive demo
You send 20 clean shipping labels to GPT-4o with a prompt that says “extract tracking number, carrier, addresses, and service type as JSON.” It nails 16 out of 20. That’s 80%. Stakeholders see the demo and approve the project. Nobody asks what happened to the other four.
Stage 2: The prompt engineering death spiral
You discover the failures: a DHL eCommerce label with the tracking number in an unusual position, a USPS label printed in thermal that’s half-faded, a FedEx label where the model confuses the shipper reference number with the tracking number because they’re both long numeric strings near the barcodes. So you add a few-shot examples. You add chain-of-thought reasoning. Your prompt is now 4,000 tokens. Each inference costs $0.04 and takes ~8 seconds. Accuracy creeps to 85%. You’ve spent six weeks on prompt engineering.
Stage 3: The existential stall
Operations need 97%+ accuracy to replace manual data entry. You’re at 85%. Every percentage point above that requires exponentially more prompt engineering effort. You’ve hit the ceiling of what in-context learning can do for a domain where the model has never been trained on the visual conventions that distinguish a UPS 2nd Day Air label from a UPS Ground label.
Where VLMs Touch the Logistics Execution Chain
The reference frame matters. A VLM in logistics doesn’t exist in a vacuum; it sits inside an execution chain where every token it generates can update a WMS record, trigger a replenishment order, release a shipment, or shift liability between parties.
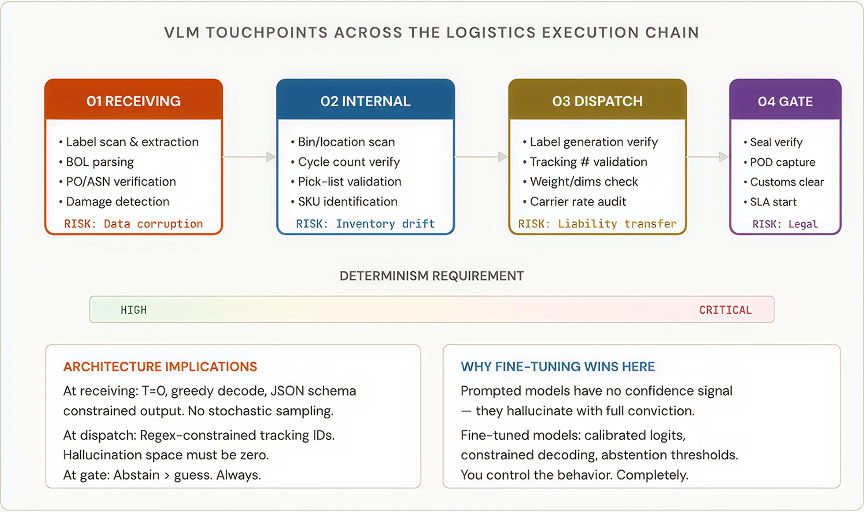
The critical insight here, one I didn’t fully internalize until I’d seen it fail in production, is that a logistics VLM is not generating content. It is validating physical reality against enterprise data. The model’s job at receiving is not “describe this label.” It’s “extract these 15 specific fields with zero hallucination, cross-reference them against the ASN, and flag discrepancies.” That’s verification, not generation.
A frontier model accessed via API has no abstention mechanism. It doesn’t know when it doesn’t know. A fine-tuned model with calibrated confidence scores and a hard threshold, if confidence < 0.85: return "REVIEW_REQUIRED" , gives you the one thing that matters most in logistics AI: the ability to say “I’m not sure” instead of guessing.
Why 2B Parameters Beat 70B on Shipping Labels
This is the claim that draws the most skepticism, so let me be precise about why it’s true.
A 70-billion-parameter model’s capacity is distributed across the entire visual and textual distribution of the internet. A 2-billion-parameter model fine-tuned on 100,000 shipping label images has focused its entire capacity on exactly your domain. Its embeddings have been reshaped to encode carrier-specific layouts. Its attention patterns have been trained to link barcode regions to corresponding text fields.
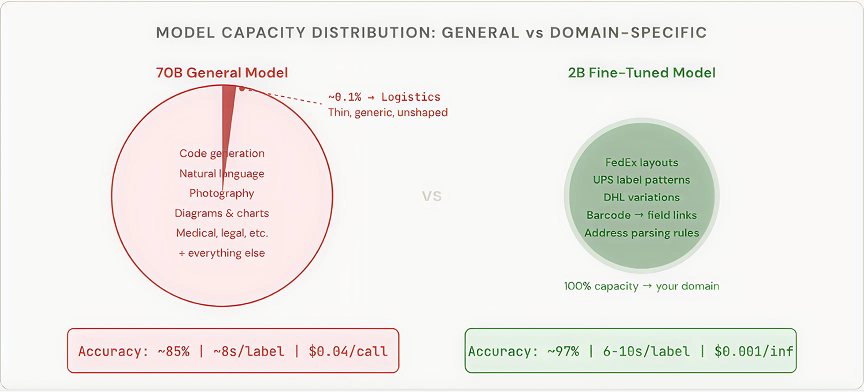
The concentration produces a second-order advantage that’s equally important: predictable failure modes. When a 70B model fails on a shipping label, the failure is often bizarre; it hallucinates a city name that doesn’t exist. When a 2B fine-tuned model fails, it typically fails in ways that map directly to gaps in your training data. These are solvable problems. That’s engineering, not prompt-twiddling art.
The Synthetic Data Pipeline: Your Actual Moat
“We don’t have enough labeled data” is the excuse I hear most often from teams that have stalled at the prompting phase. It sounds reasonable. But it fundamentally misunderstands the domain.
Shipping labels are not photographs of cats. They are rule-generated artifacts. Every major carrier publishes label specifications. Addresses follow country-specific formats. Tracking numbers follow carrier-specific patterns. This means you can generate your training data. Not as a compromise, as an advantage.
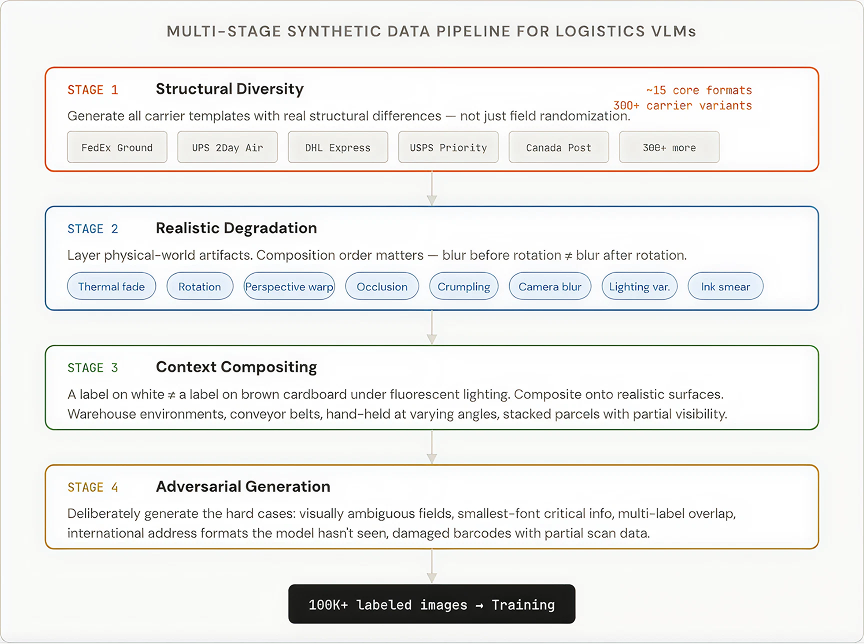
Building this pipeline was, by a wide margin, the largest engineering investment in the entire VLM project. Once built, this pipeline is a permanent, compounding asset. When we add a new carrier, we add a template. When we discover a new failure mode in production, we add a targeted augmentation layer. The pipeline is the moat, not the model.
On-Device Reality: Why “Just Use the API” Fails in Logistics
Logistics scanning happens in warehouses with poor WiFi, on delivery trucks in rural areas, at cross-border facilities with restricted networks, and at the point of scan, where connectivity simply cannot be assumed.

This isn’t a nice-to-have. For most real-world logistics scanning scenarios, on-device or on-premises inference is a hard architectural constraint. If your model can’t run locally, it can’t serve the use case. And if it can’t serve the use case, it doesn’t matter how many parameters it has.
The Decision Framework: When to Fine-Tune vs. When to Prompt
I’m not arguing that fine-tuning is always the right answer. The decision depends on where your use case sits on five dimensions:
For logistics document understanding, shipping labels, bills of lading, customs forms, and proof-of-delivery slips, every single factor points toward fine-tuning. If you’re working on a logistics VLM and you’re still in the prompt-engineering phase, it’s worth asking honestly: are you there because it’s the right approach, or because it’s the comfortable one?
What I’d Tell My Past Self
If I were starting this work over, knowing what I know now:
BUDGET YOUR TIME CORRECTLY
Most teams invert this ratio. They spend weeks tweaking hyperparameters and comparing model architectures when the real problem is the quality and distribution of the training data.
Start with a prompting baseline on day one
Not to ship, to measure. Send 200 real-world images to the best frontier model with a reasonable prompt. Measure accuracy per field, per carrier, per degradation level. This is your benchmark.
Build the data pipeline before choosing the model
Your data pipeline determines your ceiling. The model is just a function mapping input to output. If your training data doesn’t cover the real-world distribution, no architecture will save you.
Quantize from the start, not at the end
If the model needs to run at 4-bit on a mobile device, use quantization-aware training (QAT). Post-training quantization costs you 5-15% accuracy. QAT costs you 1-3%. That gap is the difference between production-viable and prototype-only.
Invest in carrier-specific evaluation, not aggregate metrics
An aggregate accuracy of 92% means nothing if FedEx Ground is at 99% and DHL eCommerce is at 71%. You need per-carrier, per-field, per-degradation-level metrics.
The Bigger Picture
The VLM space is racing toward ever-larger, ever-more-general models. That trajectory is correct for general-purpose applications, chat assistants, content creation, and open-ended visual Q&A. But it’s creating a massive blind spot for the enterprise.
Most logistics visual understanding problems have bounded visual vocabularies, structured outputs, hard accuracy requirements, real deployment constraints, and high error costs that propagate through enterprise systems. These problems are poorly served by general-purpose frontier models and extremely well served by small, focused, fine-tuned models with deterministic AI decoding and constrained output.
The teams that figure this out will build durable advantages. Not because model training is hard; any competent ML engineer can fine-tune a VLM. But because the infrastructure is hard. The synthetic data pipelines cover 300+ carriers. The domain-specific evaluation frameworks. The quantization-aware training loops. The on-device and on-premise deployment tooling. That infrastructure compounds over time and becomes very difficult to replicate.
Entropy belongs in research labs. Determinism belongs on the dock floor. When your VLM behaves like infrastructure rather than a chatbot, it becomes trusted. Not impressive. Trusted. And in logistics, trust is the only metric that matters.


